Agent:从规则系统到大语言模型智能体
最近两年,“Agent”几乎成了 AI 世界里最常见的词。但如果只把它理解成“会调用工具的大模型”,其实还不够。更准确地说,智能体首先是一种为了目标而行动的系统,大语言模型只是今天最强、最通用的一种实现方式。
这篇文章基于 Datawhale《Hello Agents》第一部分“智能体与语言模型基础”三章内容浓缩整理,同时参考了 Anthropic 与 Hugging Face 对现代 Agent 的定义与工程经验,去掉了原教程中的代码示例,只保留我认为最值得建立的知识骨架。
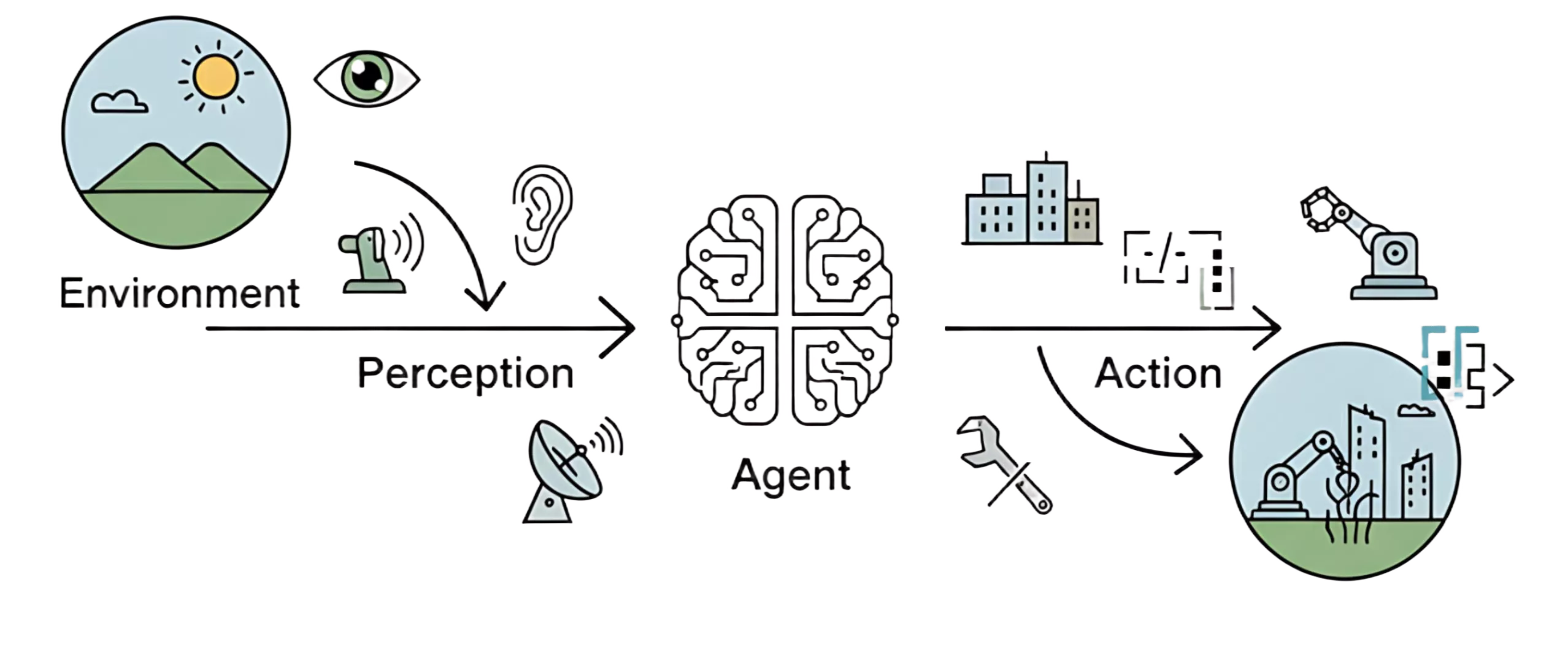
什么是智能体
在人工智能里,智能体可以理解成一个持续和环境交互的行动者:它通过传感器获取信息,通过内部机制做判断,再通过执行器对外部世界施加影响,最终朝某个目标前进。
这里真正关键的不是“会不会说话”,而是有没有完整闭环:
- 有环境,不是悬空地生成文本
- 有感知,能接收用户输入、API 返回值、外部状态变化
- 有行动,能输出回答、调用工具、执行任务
- 有目标,知道自己为什么行动
- 有自主性,不只是机械执行一条固定脚本
所以,聊天机器人不一定是智能体,工作流也不一定是智能体。只有当系统能够根据上下文持续判断“下一步该做什么”,并依据反馈调整行为时,我们才更接近在谈论真正的 Agent。
智能体可以怎么分类
如果把智能体的发展压缩来看,大致可以从三个角度理解它。
第一种是按决策能力分类。
- 反射式智能体:看到刺激就立刻响应,像恒温器一样靠“条件-动作”规则工作。
- 基于模型的智能体:内部开始有世界模型,不只看眼前,也会结合历史状态判断。
- 基于目标的智能体:不只是响应,而是为了达到某个未来状态主动规划。
- 基于效用的智能体:会在多个目标之间权衡,追求“更优”而不是“达到就行”。
- 学习型智能体:不完全依赖人类预设,而是能从经验和反馈中更新策略。
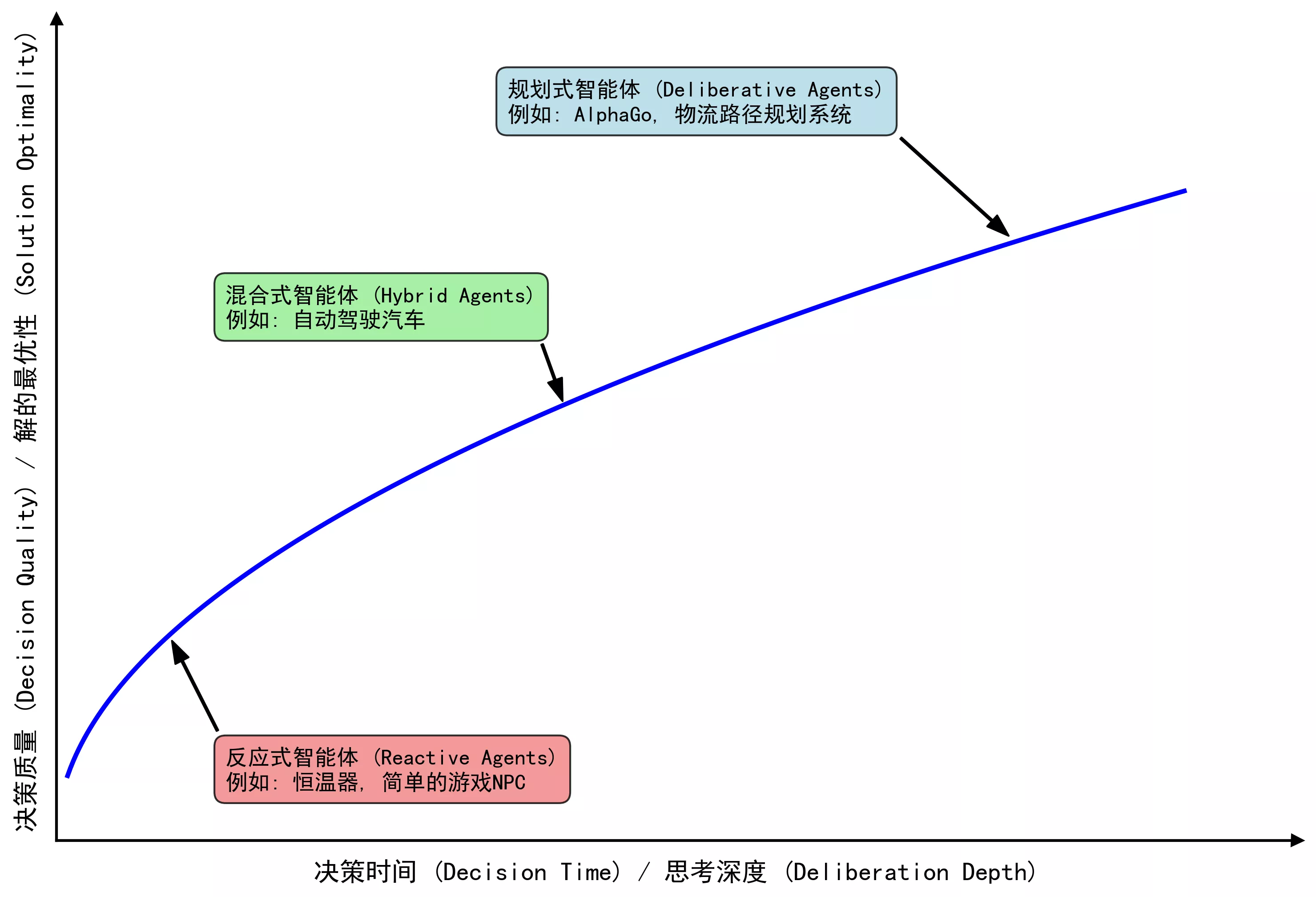
第二种是按行为节奏分类。
- 反应式:快,但短视,适合高实时场景。
- 规划式:会先思考再行动,适合复杂长任务。
- 混合式:局部快速反应,整体长期规划,这是现代 LLM Agent 很常见的形态。
第三种是按知识表示分类。
- 符号主义:知识写成规则、逻辑、图谱,可解释但脆弱。
- 亚符号主义:知识隐含在神经网络参数中,模式识别强但不透明。
- 神经符号混合:让统计学习和结构化推理协同工作,这也是今天很多 Agent 设计的实际方向。
智能体为什么不是新东西
今天 Agent 爆火,很容易让人误以为它是大模型时代突然发明出来的概念。其实不是。智能体思想几乎伴随了整个人工智能史,只是实现方式在不断变化。
早期人工智能的主流是符号主义。那一代研究者相信,智能的本质是对符号进行操作,只要把知识写成规则,再配上推理机,机器就能表现出专家水平。专家系统 MYCIN 就是这一路线的代表,它能在狭窄医疗领域给出高质量诊断建议。SHRDLU 则更进一步,把自然语言理解、规划和行动放进同一个“积木世界”中,已经很像早期的环境交互型 Agent。
但问题很快暴露出来了。规则系统的瓶颈不在于“有没有规则”,而在于现实世界根本写不完。常识太多、例外太多、环境太动态,知识获取成本极高,系统也极其脆弱。一旦离开封闭场景,很多看似聪明的系统立刻失效。ELIZA 这种聊天程序更说明了另一点:看起来像理解,并不等于真的理解。
也正是在这种困境里,马文·明斯基提出了“心智社会”的观点。他不再把智能看成一个完美中央大脑,而认为它更像许多简单过程协同工作的结果。这个思想后来深刻影响了多智能体系统:复杂智能可以来自分工、协作、通信与涌现,而不一定来自单一超强模块。
接着,联结主义和深度学习改变了局面。规则不再由人硬编码,而是通过数据训练出来。强化学习又让“试错式决策”成为可能,AlphaGo 就是典型例子。等到大规模预训练出现后,模型第一次在通用语料上获得了大范围世界知识、语言能力与初步推理能力,现代 Agent 所需的“大脑”才真正成熟。

换句话说,今天的 Agent 不是凭空诞生的,它是符号主义的目标导向、强化学习的交互决策、深度学习的表征能力,以及大模型的通用语言接口共同汇合后的结果。
现代 Agent 的运行方式
无论外壳多花哨,现代智能体的核心循环都很朴素:感知、思考、行动、再观察。
- 感知:接收用户请求、工具返回、环境变化
- 思考:拆任务、做判断、决定下一步
- 行动:调用工具、生成回答、修改环境
- 观察:读取行动结果,并把它送回下一轮推理
Hugging Face 在 Agents Course 里把这个过程概括成 Thought -> Action -> Observation。这套表达非常重要,因为它把“大模型生成一段文本”变成了“系统在循环中逐步完成任务”。
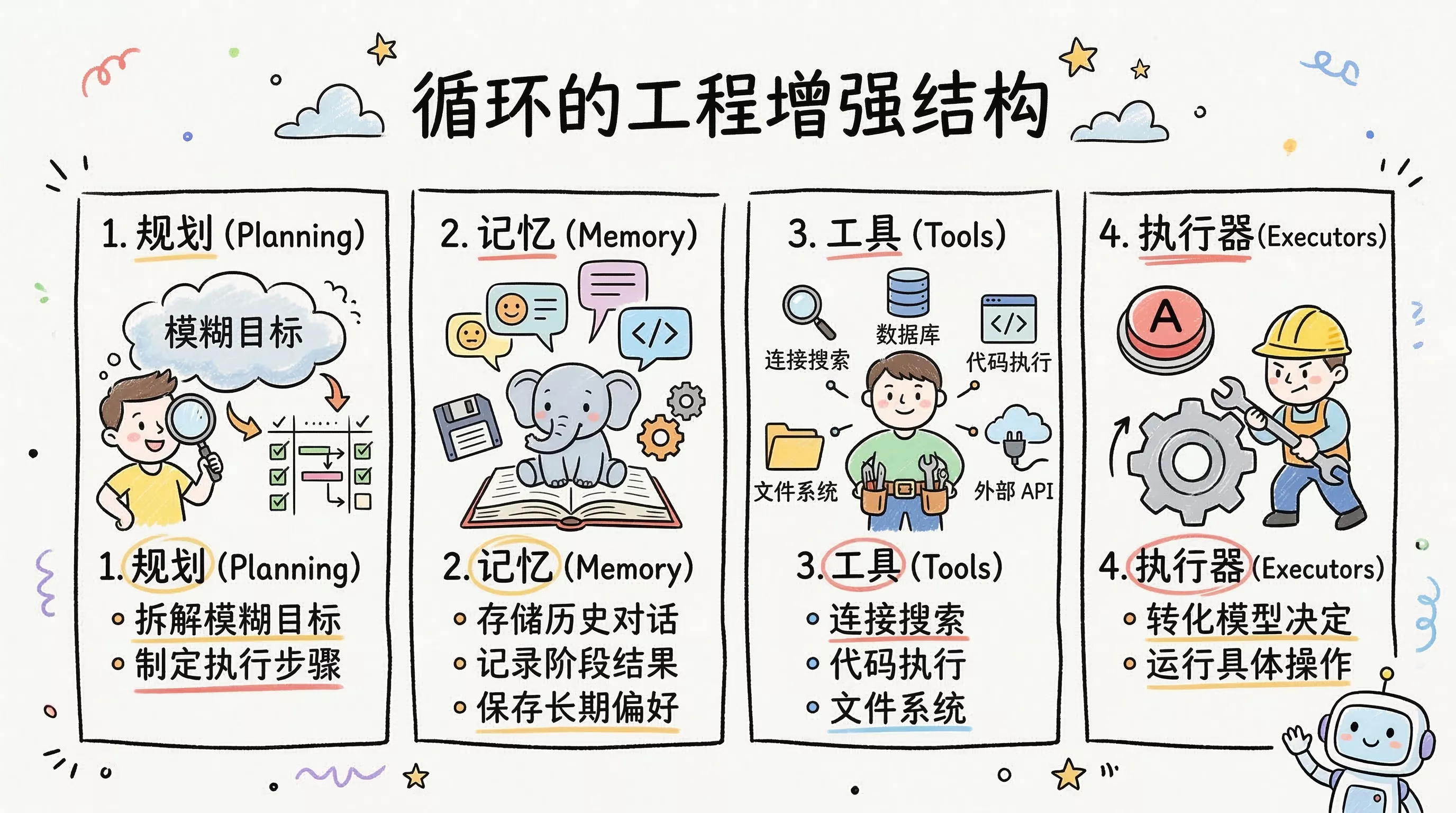
在工程上,这个循环通常还会补上几层关键结构:
- 规划:把模糊目标拆成可执行步骤
- 记忆:保留历史对话、阶段结果和长期偏好
- 工具:连接搜索、数据库、代码执行、文件系统或外部 API
- 执行器:真正把模型决定转成可运行操作
这也是为什么我更愿意把 Agent 理解成“带外部行动能力的推理系统”,而不只是“会聊天的模型”。
大语言模型为什么成为 Agent 的大脑
如果说传统智能体的问题,是规则太硬、泛化太弱,那么大语言模型解决的是另一个层面的问题:它让系统第一次拥有了相对通用的语言理解、知识压缩和任务迁移能力。
理解这一点,最简单的线索就是语言模型本身的演进:
- N-gram 时代:只能看很短上下文,数据稀疏严重。
- RNN/LSTM 时代:开始有序列记忆,但训练难、并行差。
- Transformer 时代:依靠自注意力直接建模长距离依赖,并能大规模并行训练。
- Decoder-Only 时代:通过“预测下一个 token”统一对话、写作、推理与代码生成,最终形成今天的 GPT、Claude、Qwen、Llama 这类基础模型。
Transformer 的关键价值不只是“更强”,而是它把语言建模这件事变成了可以持续扩展的工程体系。参数量、数据量和算力投入之间存在明显的缩放规律,这意味着模型能力可以随着规模增长而稳定上升。许多原本很弱的能力,比如指令遵循、上下文学习、链式推理,往往会在模型大到一定程度后突然变得可用。
这也是现代 Agent 能成立的前提:如果大模型没有足够好的理解、推理和工具调用能力,所谓智能体只会退化成一个不稳定的脚本生成器。
但大语言模型并不等于智能体
这一点反而是初学者最容易混淆的地方。
LLM 只是 Agent 的认知核心,不是完整 Agent。它最擅长的是语言概率建模,而不是天然可靠地感知世界、维护记忆、调用外部系统或保证事实正确。
因此,真正落地时必须看到它的边界:
- 幻觉:会一本正经地生成错误事实
- 知识时效性有限:训练后发生的新信息默认不知道
- 上下文窗口昂贵且有限:输入越长,成本越高,稳定性也越差
- 推理并不总可靠:复杂任务中仍会遗漏约束、走错步骤
- 价值观与偏见会继承训练数据问题
也正因如此,提示工程、分词器、上下文管理、检索增强、外部工具调用和结果校验,才不是“边角料”,而是智能体工程的主体。
Agent、Workflow 和“伪 Agent”
Anthropic 在《Building Effective AI Agents》里给了一个很有用的区分:不是所有 agentic system 都应该叫 Agent。
- Workflow:LLM 和工具走预定义代码路径,流程更可控、更稳定。
- Agent:LLM 自主决定下一步做什么、调用什么工具、何时停止,灵活性更高。

这个区分非常重要。因为现实里很多产品虽然叫 Agent,本质上更像“加了模型的工作流”:路由、分类、检索、模板生成、执行固定步骤。这类系统并不低级,反而常常更实用。对于边界清晰、流程稳定的任务,Workflow 往往比全自主 Agent 更便宜、更快、更可靠。
只有当任务具备这些特征时,Agent 才更值得上场:
- 目标比较模糊,不能提前写死全部步骤
- 中途需要根据外部反馈动态修正计划
- 工具选择和任务拆解依赖模型判断
- 单次调用无法解决,需要循环推进
所以一个成熟的认识应该是:不是“能不能做成 Agent”,而是“这件事究竟该做成单轮调用、工作流,还是自治 Agent”,其实就是视场景而定,各有优势。
基于大语言模型的智能体,究竟新在哪里
如果只把现代 Agent 理解成“LLM + 一个工具调用接口”,其实还是太窄了。
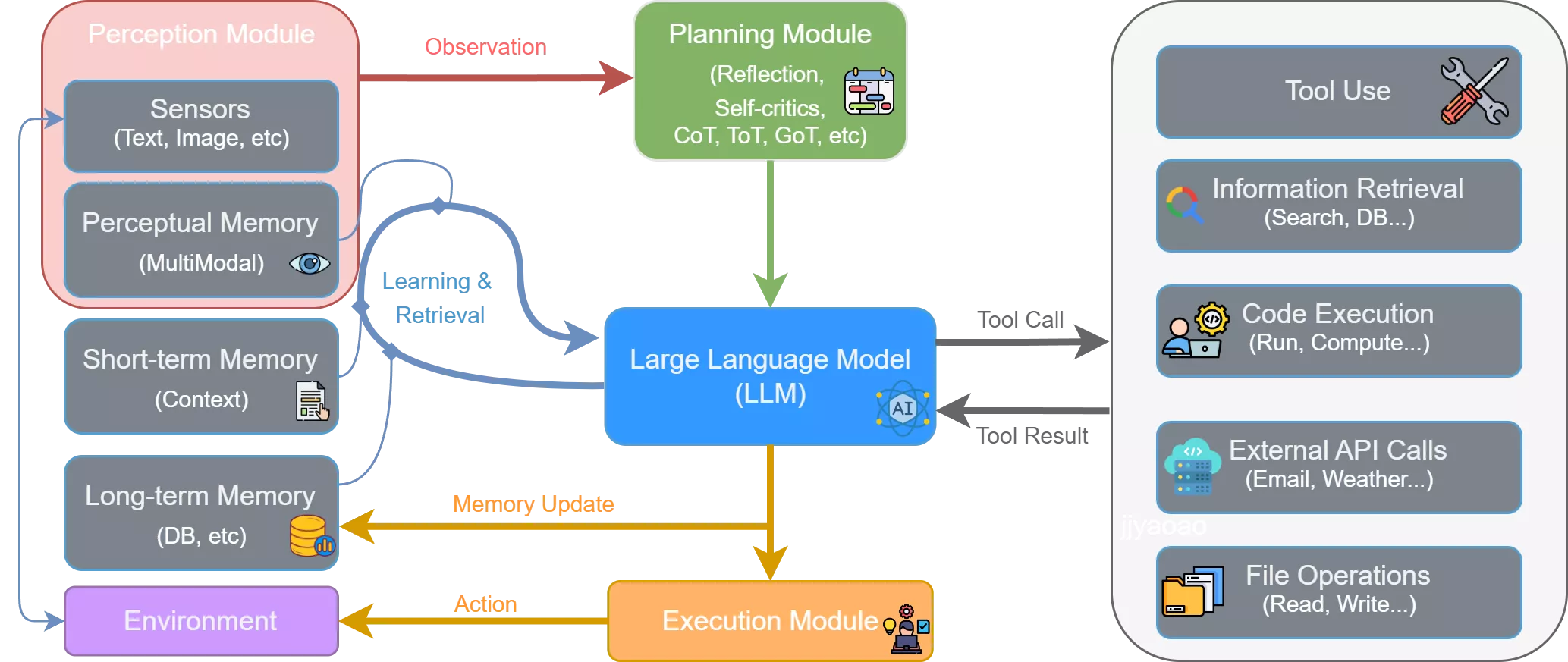
Anthropic 在官方文章里更倾向于把它理解成一种 augmented LLM,也就是被多种能力增强后的大语言模型:模型本身负责理解和推理,外层再为它补上检索、工具、记忆和执行环境。
这样一来,现代 LLM Agent 至少会同时包含几层东西:
- 模型本体:负责理解目标、分解任务、生成下一步决策。
- 工具系统:负责接触真实世界,比如搜索、读写文件、执行命令、访问数据库、调用外部 API。
- 记忆系统:负责保留短期上下文与长期偏好,避免每一轮都从零开始。
- 规划机制:把一句模糊指令拆成若干个可执行动作,并在中途动态修正。
- 反馈闭环:每执行一步都读取环境返回值,再决定下一步,而不是一次性把整条路径写死。
从这个角度看,现代 LLM Agent 的“新”,并不只是模型更聪明了,而是它第一次让一个足够通用的语言核心,能在开放环境里承担协调者的角色。它既可以像规则系统那样追求结构,又不像传统规则系统那样必须提前把所有情况编码完。
LLM Agent 的关键不在“会不会调用工具”,而在“会不会管理上下文”
当任务变复杂后,真正影响 Agent 表现的,往往不是模型参数本身,而是上下文怎么组织。
一个成熟的 LLM Agent 通常要持续处理这些问题:
- 当前轮次到底该给模型喂哪些信息
- 哪些历史结果应该进入短期上下文,哪些应该进入长期记忆
- 哪些工具结果应该原样返回,哪些应该先做压缩和结构化
- 哪一步必须让人类介入确认,哪一步可以放权给模型
这也是为什么现在越来越多人开始强调 context engineering。对 Agent 来说,上下文不是“聊天记录越多越好”,而是“在有限上下文窗口里,给模型最必要、最干净、最可执行的信息”。
Agent 的工程核心,其实是上下文管理、工具边界和反馈回路的设计。模型只是大脑,但真正让系统稳定工作的,是这套外围结构。
一个好用的 LLM Agent,通常会遵守这些工程原则
结合 Anthropic 的官方经验,以及 Hugging Face 和 LangChain 这些框架文档里反复强调的点,现代 Agent 的工程原则压缩成下面几条:
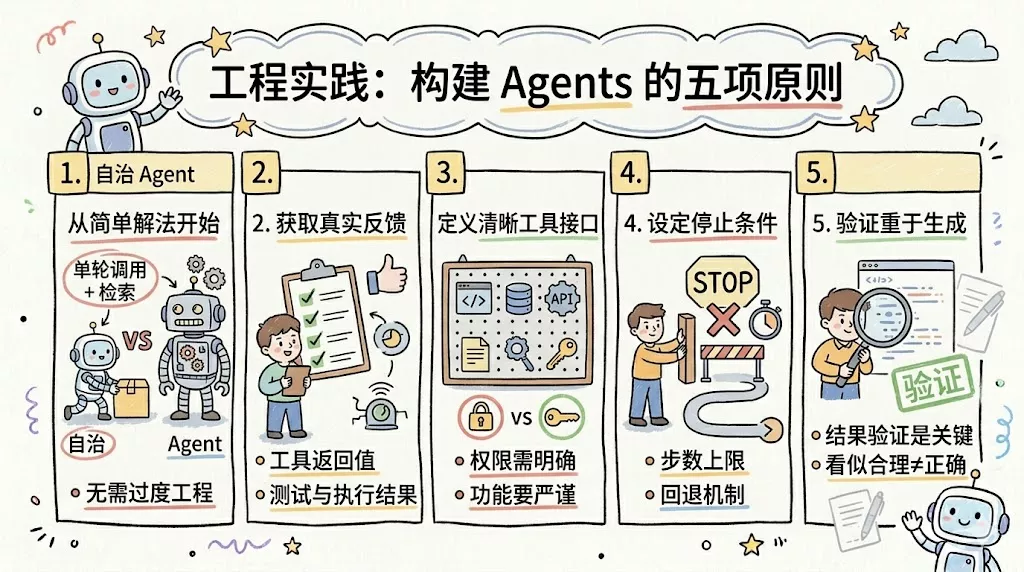
- 先从最简单的解法开始:很多任务其实单轮调用加检索就够了,不必一上来就上自治 Agent。
- 每一步都尽量拿到真实反馈:工具返回值、代码执行结果、测试结果,都是比“模型自我感觉”更可靠的地面真相。
- 工具接口要清晰、权限要明确:工具说明越模糊,模型越容易乱用;权限越失控,系统越危险。
- 要有停止条件:Agent 不能无限循环,通常需要步数上限、失败回退或人工确认节点。
- 验证比生成更重要:尤其在代码、数据处理和外部操作场景里,能否验证结果,往往比能否先写出一个看似合理的答案更关键。
多智能体编排,为什么会成为下一步
当单个 Agent 要处理的事情越来越多,一个自然的问题就会出现:是不是可以把它拆成多个更专门的 Agent,各自处理一部分工作?
这就是多智能体编排的起点。
LangChain 官方文档把多智能体的动机总结得很直接,开发者通常想做 multi-agent,本质上是在追求三件事:
- 上下文管理:不同任务需要不同背景知识,不想把所有东西都塞进一个巨大的 prompt 里。
- 分布式开发:让不同团队分别维护不同能力模块,再把它们组合起来。
- 并行化:把独立子任务交给多个 worker 同时执行,换取速度和上下文隔离。
也就是说,多 Agent 并不是“更高级的单 Agent”,而是一种为了解决复杂性而做的系统拆分。
但同样重要的一点是:不是所有复杂任务都需要多智能体。 如果一个单 Agent 已经能用清晰工具和合适提示稳定完成任务,那硬拆成多 Agent 反而会增加成本、延迟和协调难度。哎,只能说脱离不了物理学啊🤣,以及人类的社会定律。
多智能体编排的几种典型模式
目前比较常见的多智能体组织方式,大致可以分成下面几类。
1. Supervisor / Subagents
这是最常见、也最像“项目经理带多个专员”的结构。
- 一个主 Agent 负责维护总目标和全局上下文
- 若干子 Agent 被包装成专门能力模块
- 主 Agent 决定什么时候调用谁、给谁什么输入、最后如何汇总结果
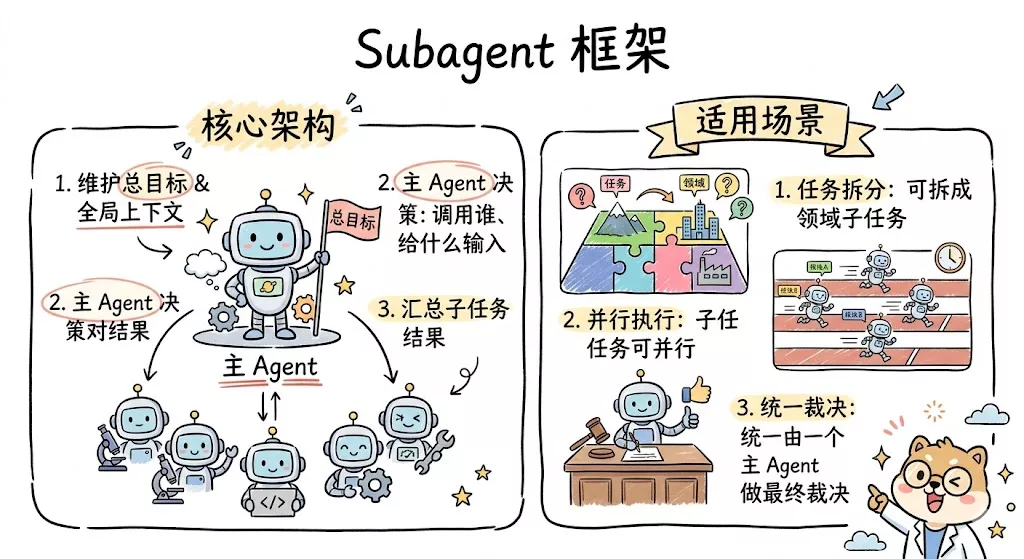
LangChain 官方把这种模式称为 subagents,特点是集中控制、上下文隔离、适合并行,而且子 Agent 通常不直接面对用户,而是把结果返回给主 Agent 再统一输出。主流的code agent基本都支持, codex也在上周支持了该agent编排方式
这类结构很适合:
- 一个任务天然可拆成多个领域子任务
- 子任务之间可以并行
- 希望统一由一个主 Agent 做最终裁决
2. Handoffs
这类模式更像“把话筒交出去”。
- 当前 Agent 在某个阶段判断自己不再适合继续处理
- 系统把控制权切换给另一个更合适的 Agent
- 后续由新的 Agent 继续和用户交互
这种结构更适合用户真的需要和多个“角色”连续对话的场景,比如从客服转交技术支持,再转交退款专员。它的优点是自然、连贯,但并不擅长大规模并行。
3. Router
Router 本质上是先分类,再派发。
- 先判断当前请求属于哪一类
- 再把它路由给最适合的专门 Agent
- 必要时把多个结果合成最终回答
它适合输入类型差异很大、每类任务都有成熟处理链路的系统,比如客服工单分流、不同领域知识问答、不同难度任务分配到不同模型。
多智能体真正解决了什么问题
如果把多智能体的价值说得更具体一点,我觉得至少有四个现实收益。
1. 降低上下文污染
单 Agent 最怕一边做规划、一边查资料、一边跑命令、一边读日志,最后主上下文被大量中间噪声淹没。多 Agent 可以把探索、分析、实现拆到不同上下文窗口里,主线程只保留关键结论。
2. 提高并行效率
只要任务之间依赖不强,就能把搜索、调研、代码审查、测试分析并行跑掉。这在大型代码库、跨模块改动、复杂信息检索中非常有价值。
3. 让角色分工更清楚
不是每个 Agent 都要会一切。有人擅长探索代码库,有人擅长制定计划,有人擅长做修改,有人只负责审查或验证。明确角色边界后,系统会更可控。
4. 让系统更易维护
当不同团队分别维护不同子 Agent 或技能包时,系统可以像模块化软件一样演化,而不是把所有逻辑都塞进一个越来越庞大的总提示词里。
但多智能体也会带来新的成本
多智能体不是白送的能力,它也会引入新的问题。
- 调用成本更高:更多 Agent,通常意味着更多模型调用。
- 延迟更高:尤其是串行 handoff 或多轮汇总时。
- 协调更难:多个 Agent 可能重复劳动,甚至给出互相冲突的结果。
- 共享状态复杂:谁能看到什么上下文,谁负责最终决策,必须定义清楚。
- 并行写入容易冲突:在代码修改类任务里,如果多个 worker 同时改同一块内容,合并成本会上升。
所以更务实的做法通常是:把多智能体当作一种“按需拆分复杂度”的工程手段,而不是默认答案。
Claude Code 和 OpenCode,怎么把多 Agent 落到工程里
如果前面还是概念层,那 Claude Code 和 OpenCode 这类 agentic coding 工具,就已经把多 Agent 的思路做成了具体产品。
Claude Code:主会话 + 内建 / 自定义 subagents
Anthropic 官方文档里,Claude Code 已经明确支持 subagents。它把子代理定义成一种专门处理特定任务的 AI 助手,每个 subagent 都有自己的:
- 独立 context window
- 自定义 system prompt
- 工具访问范围
- 权限模式
- 可选模型
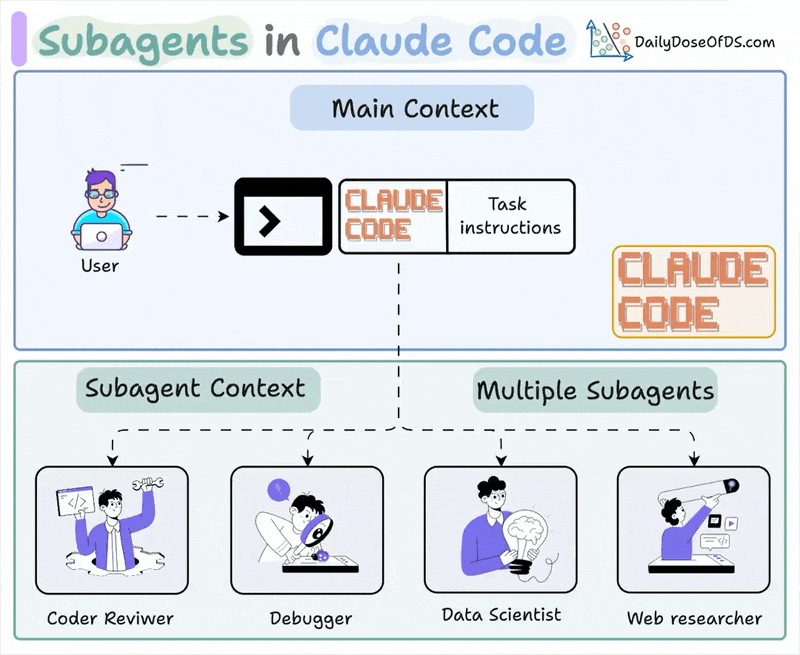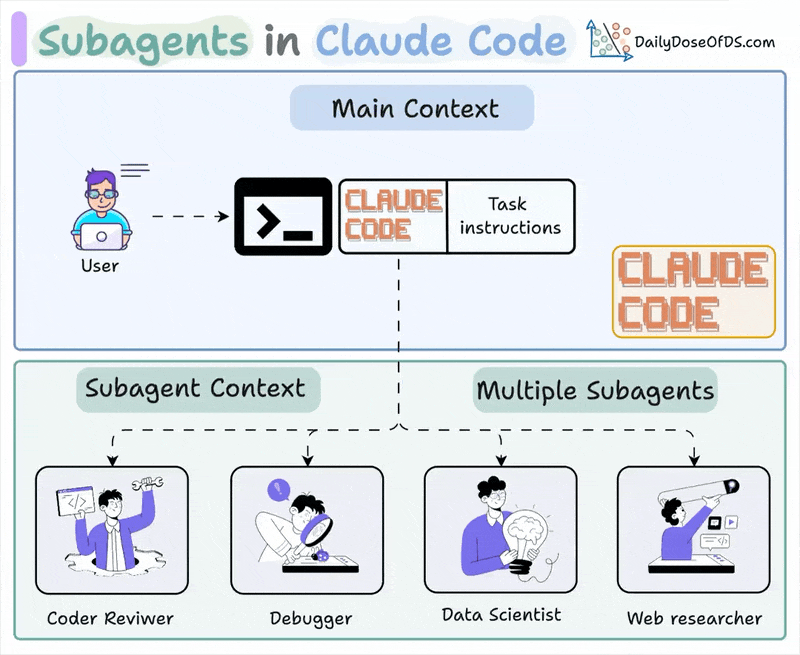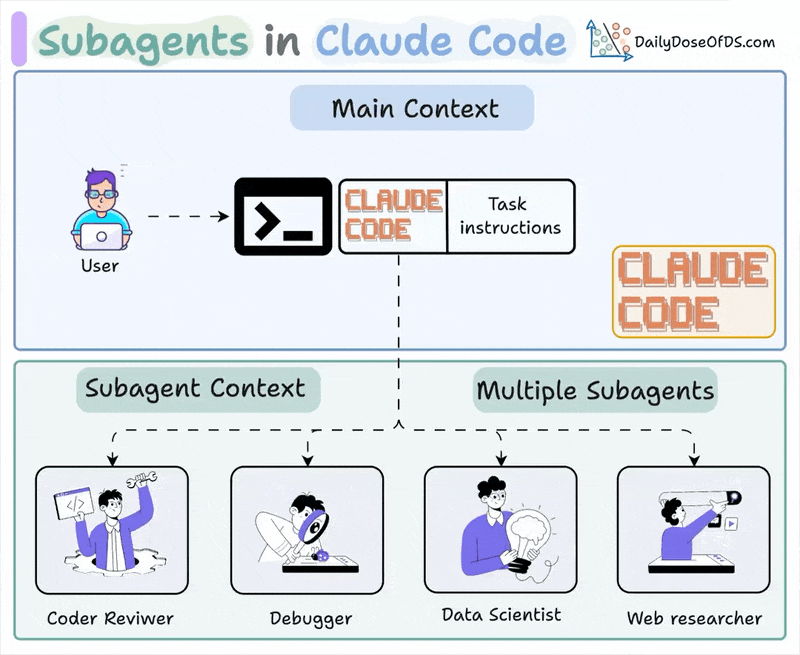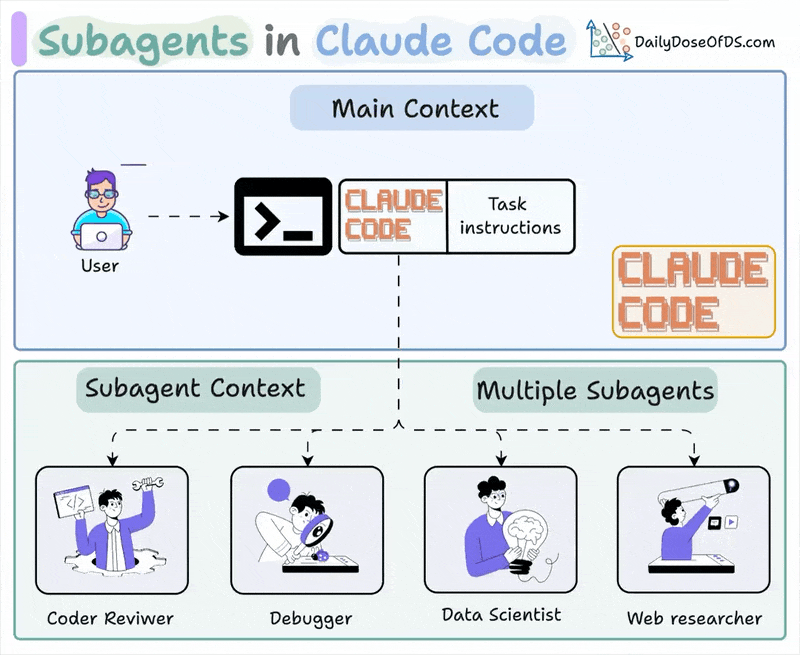
官方内建的几个子代理就很能说明问题:
- Explore:只读、快速、适合搜索和理解代码库
- Plan:只读、适合在 plan mode 里做调研
- general-purpose:可处理复杂多步任务,也可执行修改
这套设计很典型:主 Agent 保留总任务与主上下文,遇到搜索、调研、复杂子任务时,自动或手动委托给 subagent;subagent 在隔离上下文里完成工作,再把结果回传给主 Agent 继续决策。它的优势是:
- 能明显减少主上下文膨胀
- 能给不同子任务配置不同模型和权限
- 能把探索、修改、审查拆开,降低串扰
Claude Code 还允许用户把 subagent 写成 Markdown + YAML frontmatter,按项目级或用户级复用。
由于claude code 默认不能接入第三方模型,实现多模型编排只能依靠mcp、skill连接其他模型调用实现多模型agent,闭源产品嘛,毕竟claude code也主要是为了卖自家模型
OpenCode:primary agents + subagents + child sessions
OpenCode 的官方文档把 agent 也分得很清楚:它有两类 agent。
- Primary agents:主代理,直接承接当前会话
- Subagents:子代理,由主代理自动调用,或由用户用
@显式唤起
它的内建结构同样很有代表性:
- Build:默认主代理,工具权限完整,适合开发实施
- Plan:受限主代理,默认更偏只读和分析
- General:通用子代理,适合复杂搜索与多步任务
- Explore:快速只读子代理,适合代码库探索
更关键的是,OpenCode 官方文档已经把多 Agent 的几个工程点做成了产品能力:
- 子代理既可以自动触发,也可以
@general这种方式手动调用 - 子代理会创建 child session,允许主会话和子会话之间来回切换
- agent 可以分别配置
model、mode、permission、steps - 还能通过
permission.task控制某个 agent 允许调用哪些 subagents
跟Claude code的实现思路不太一样,opencode的agent不是“做一个万能主模型”,而是把不同角色拆开,再通过权限和任务分发把它们编排起来。所以还有一个伟大的叫做oh-my-opencode的项目,专门用于做多模型编排
Claude、Kimi、GLM 负责编排,GPT 负责推理,Minimax 负责速度,Gemini 负责创意。未来并非选出唯一赢家,而是统筹所有模型。模型每月变得更便宜、更智能。
还有佬友编写的配置及学习心得:
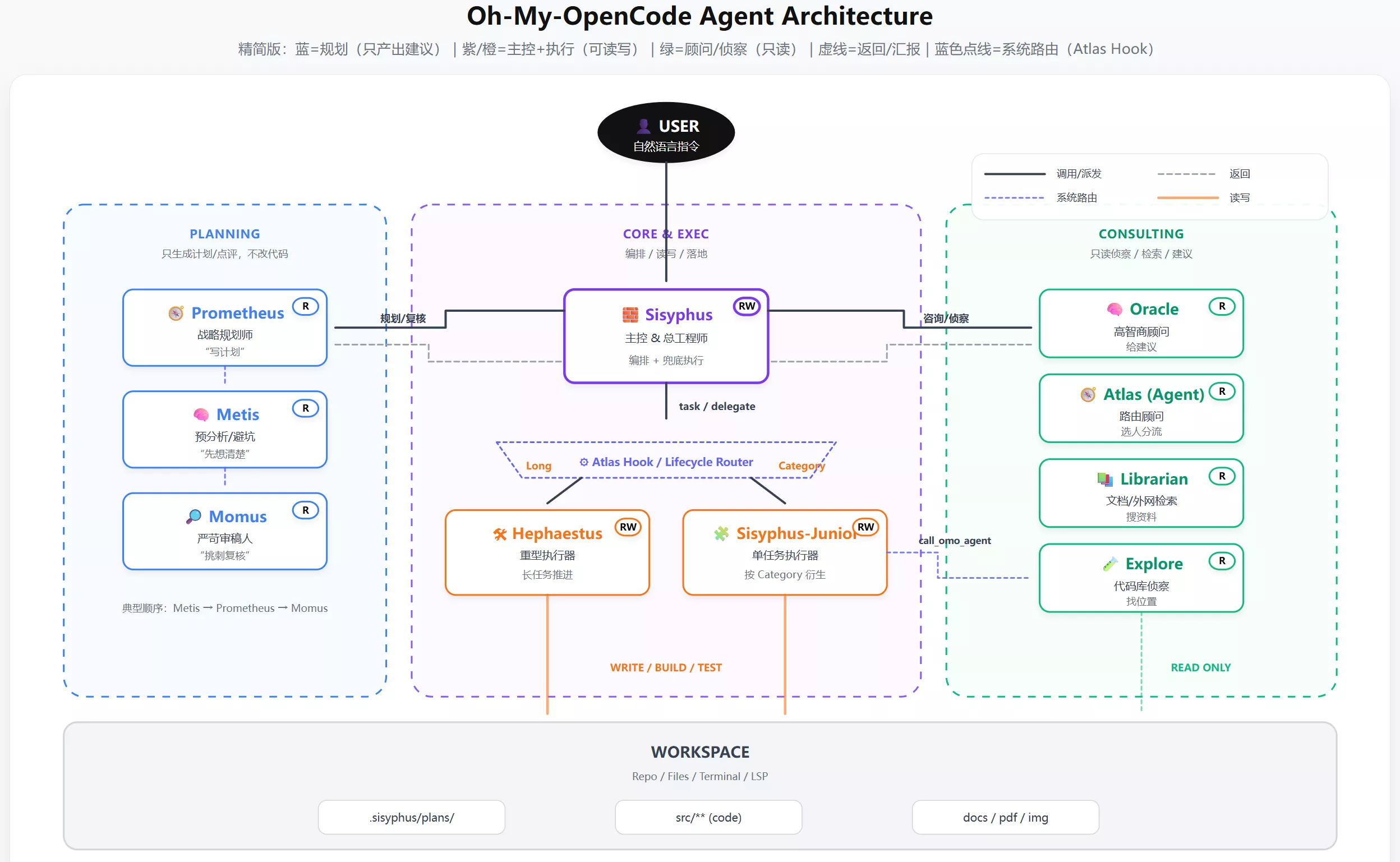
从这两个产品里,得出的共同思路
无论是 Claude Code 还是 OpenCode,它们在多 Agent 上的产品化思路其实非常一致:
- 保留一个主线程 Agent,负责总目标和最终输出
- 把探索、规划、执行、审查拆给不同子代理
- 用独立上下文窗口隔离中间噪声
- 用权限和工具边界限制每个子代理能做什么
- 在并行与集中控制之间找平衡
这也是我现在很认同的一点:在代码场景里,多 Agent 的真正价值并不只是“多开几个模型窗口”,而是把复杂任务拆成多个上下文受控、权限受控、目标明确的小系统,再由主 Agent 统一收口。
我现在对 Agent 的理解
Agent 不是一个神秘人格,而是一套围绕目标运行的闭环系统;LLM 让这套系统第一次拥有了通用的大脑,但真正决定其上限的,仍然是环境连接、工具设计、记忆管理、验证机制与整体工作流。
也正因为如此,学习 Agent 最好的路径不是一上来追逐框架,而是先把基础打稳:
- 先理解什么叫目标、环境、感知、行动
- 再理解智能体为什么会从规则系统演化到大模型系统
- 然后理解 LLM 的强项与局限
- 最后才去看 prompt、context、tool use、memory、MCP、多智能体这些更工程化的话题
这也是为什么 Hello Agents 把“智能体与语言模型基础”放在最前面。没有这层地基,后面的实践很容易只剩下“会调 API”,却不知道自己到底在构建什么。
参考资料
- Datawhale《Hello Agents》在线教程
- Datawhale《Hello Agents》GitHub 仓库
- Anthropic: Building Effective AI Agents
- Hugging Face Agents Course: What are Agents?
- Hugging Face Agents Course: Agent Steps and Structure
- Claude Code Overview
- Claude Code Subagents
- OpenCode Agents
- OpenCode GitHub 仓库
- LangChain Multi-Agent
- LangChain Subagents
- Attention Is All You Need
- Scaling Laws for Neural Language Models
- Training Compute-Optimal Large Language Models