Context Engineering:Agent 时代真正的“工作内存工程”
很多人第一次接触上下文工程,往往会把它理解成“提示词工程的升级版”。这个说法不能算错。到了 Agent 时代,上下文工程真正要解决的问题是:在有限、昂贵、会退化的上下文窗口里,到底该让模型看见什么,按什么顺序看见,以及哪些东西根本不该进去。
什么是上下文工程
如果说提示词工程关注的是“你怎么对模型说话”,那么上下文工程关注的就是“模型在这一轮推理里到底看到了什么”。
当你与大型语言模型(LLM)对话时,你实际上是在与一个具有有限工作记忆的系统互动。这种记忆被称为上下文窗口。它决定了模型在任何给定时间内能够记住多少对话内容。如果对话保持在上下文窗口范围内,模型就能记住你所说的所有内容并做出连贯的回应。但如果对话变得过长,模型就会开始遗忘早期的部分,其回应的可靠性也会随之下降。
对一个真实的 Agent 来说,进入上下文窗口的通常包括:
- 系统提示词
- 用户当前请求
- 历史对话
- 检索到的外部知识
- 工具描述与工具返回
- 长短期记忆
- 当前任务状态、计划、约束与中间结论
Datawhale 在《Hello Agents》第九章里把这件事讲得很清楚:上下文工程是一次模型调用前,如何系统化地 Gather、Select、Structure、Compress 候选信息。Context-Engineering 仓库里也用了一个很形象的区分:Prompt engineering 更像“你说了什么”,而 context engineering 更像“模型还看见了其他一切”。
所以我更愿意把上下文工程理解成一种工作内存工程。它像操作系统管理 RAM 一样,决定哪部分信息要常驻、哪部分要按需加载、哪部分应该压缩、哪部分必须隔离。
Agent 之所以比单轮聊天更依赖它,就是因为 Agent 会持续调用工具、持续产生新状态、持续把过去的结果带进下一轮。如果没有上下文工程,系统很快就会被自己生成的历史和噪声拖垮。
上下文工程 vs. 提示工程
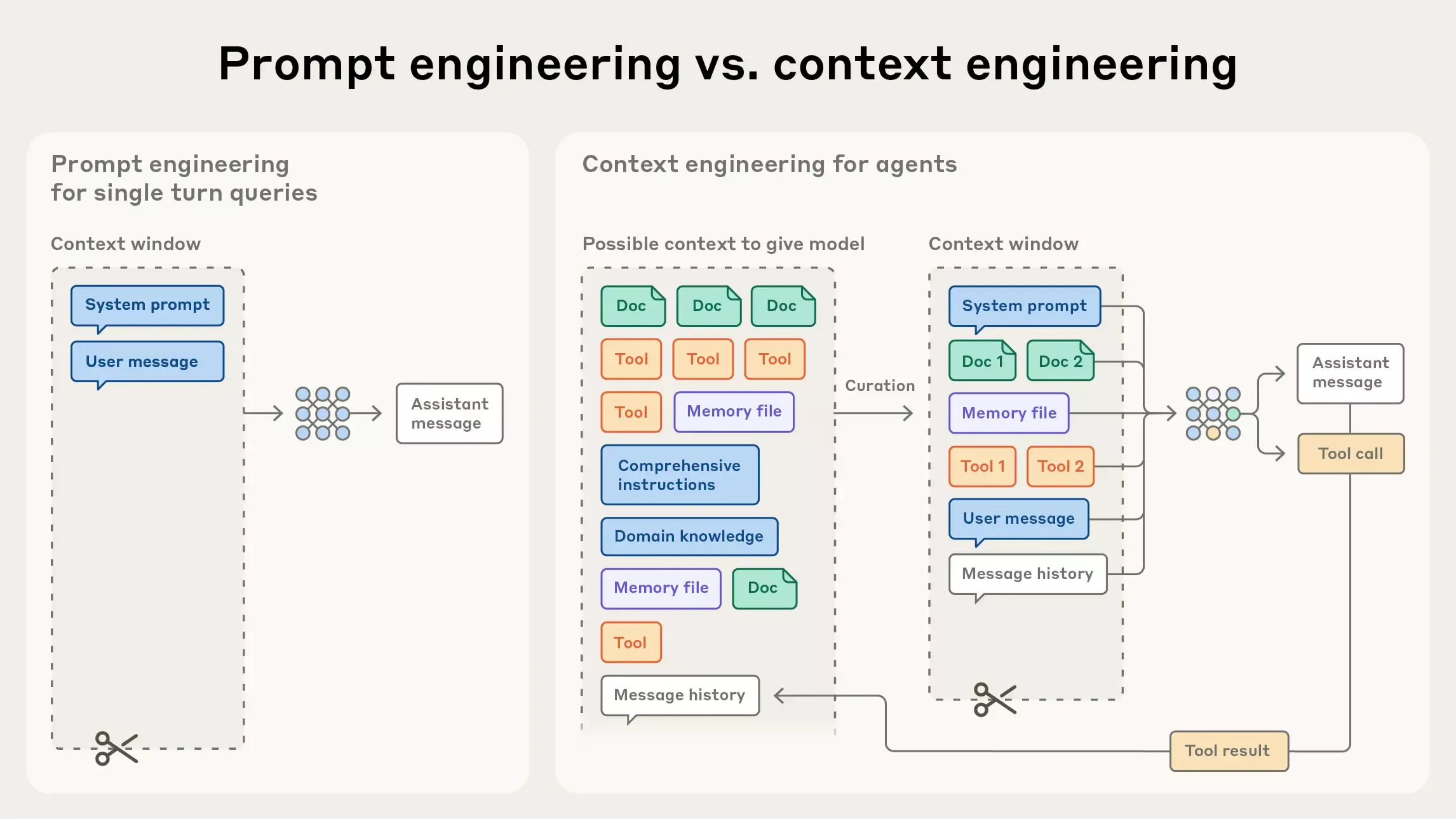
如上图所示: 上下文工程是提示工程的自然演进。
- 提示工程关注如何编写与组织 LLM 的指令以获得更优结果(例如系统提示的写法与结构化策略)
- 上下文工程则是在推理阶段,如何策划与维护“最优的信息集合(tokens)”,其中不仅包含提示本身,还包含其他会进入上下文窗口的一切信息。
在 LLM 工程的早期阶段,提示往往是主要工作,因为大多数用例(除日常聊天外)都需要针对单轮分类或文本生成做精调式的提示优化。顾名思义,提示工程的核心是“如何写出有效提示”,尤其是系统提示。然而,随着我们开始工程化地构建更强的智能体,它们在更长的时间范围内、跨多次推理轮次地工作,我们就需要能管理整个上下文状态的策略——其中包括系统指令、工具、MCP(Model Context Protocol)、外部数据、消息历史等。
一个循环运行的智能体,会不断产生下一轮推理可能相关的数据,这些信息必须被周期性地提炼。因此,上下文工程的“艺与术”,在于从持续扩张的“候选信息宇宙”中,甄别哪些内容应当进入有限的上下文窗口。
为什么 Agent 越强,上下文工程越重要
一个单轮问答模型,即使上下文管理得一般,顶多只是答案没那么稳定;
但一个会规划、会搜索、会读文件、会改代码的 Agent,一旦上下文失控,问题会被放大很多倍。Agent 的上下文不是静态的,它是会不断膨胀的。每次工具调用都会带回新的观察结果,每次推理都会留下新的中间结论,每次失败都会制造新的“历史负担”。如果你把这些东西一股脑全部塞回模型,结果通常不是“模型更聪明了”,而是:
- 成本更高
- 延迟更大
- 注意力更分散
- 中间噪声越来越多
- 关键事实反而更难被稳定调用
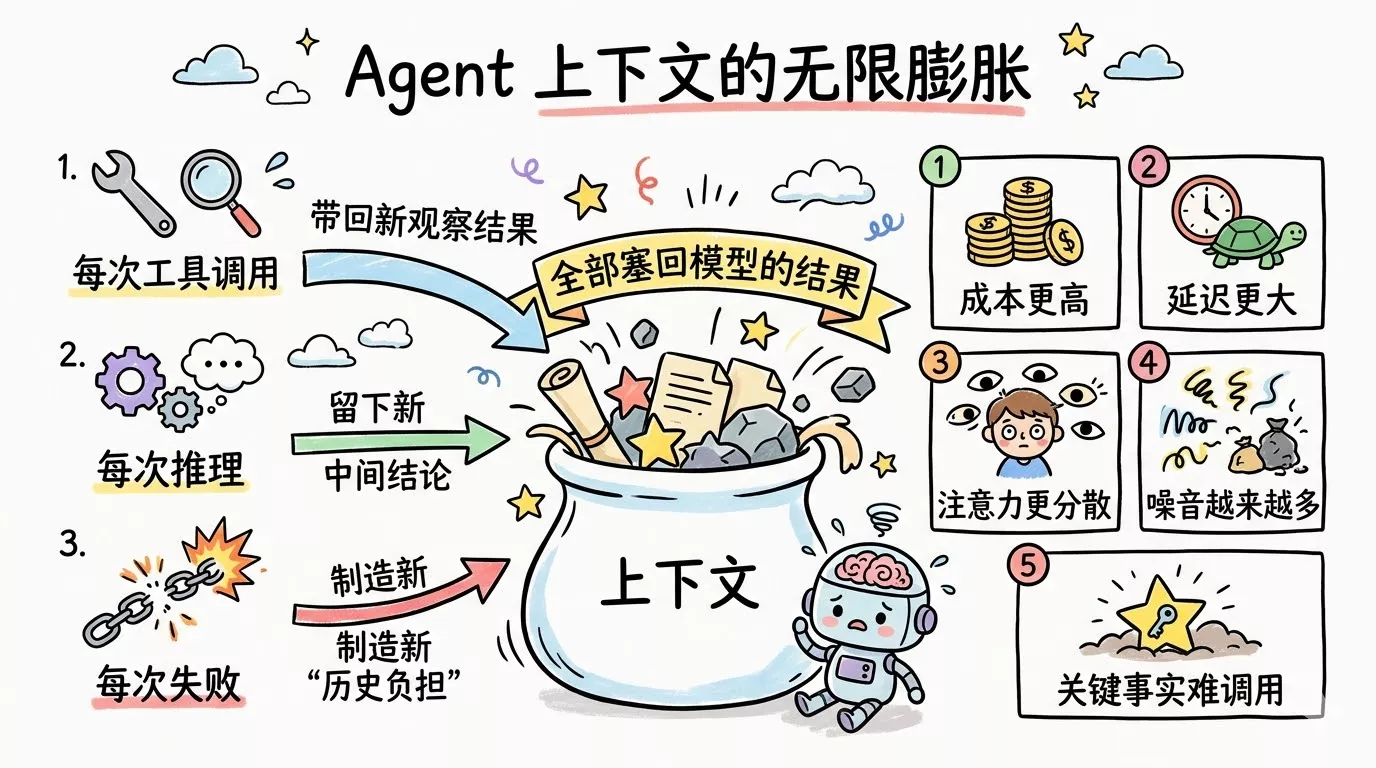
提示词只是上下文的一部分,整个系统环境才是真正长期决定系统表现的。
上下文窗口
上下文窗口本身带着明确的物理约束:
1. 上下文窗口的计量单位token
模型真正处理的不是“多少字”“多少句”,而是 token。一个 token 可能是一个词、半个词、标点,甚至只是某个词缀。也就是说,用户问题、系统提示、工具描述、RAG 片段、代码片段、函数返回结果,最后都会被统一折算成 token 预算。
这也会自然引出一个很常见的问题:英文是不是天生比中文更适合大模型?
更准确地说,很多时候并不是“英文效果更好”,而是英文在不少模型的分词器里更省 token,于是它在长对话、长文档和长思考场景里,看起来会更“划算”一些。
一个常见经验是:中文的 token 消耗往往高于英文,有时会接近英文的
1.7倍。 比如让 Claudeultrathink in English.,很多时候更大的收益并不是“英文更聪明”,而是它在长思考下更节省 token 预算。
你可以把它粗略理解成:不管是中文、英文还是法语,Claude 都不是先用某种自然语言在“脑子里”想一遍,再机械翻译出来,而是在共享的表示空间里完成表征和推断,最后才投射成具体语言。就像你心里先有“水”这个概念,落到表达层面,才会说成 water、水 或 eau。
所以,同一个意思换一种语言写 prompt,结果会变,往往不只是“语言不同”,更是 token 切分方式、上下文预算和下一 token 的概率分布一起变了。与其说这是语言问题,不如说它本质上还是生成概率问题。
2. attention 让模型能关联远处信息,也让长上下文天然更贵
不过,语言差异只是 token 预算的一面。真正决定长上下文为什么会迅速变贵、变慢、变难用的,还是底层的自注意力机制。
前文提到了当今大模型普遍采用 Transformer 及其衍生架构。它之所以能处理长文本,是因为 self-attention 允许每个 token 在生成时,去看上下文里其他 token 和自己之间的关系。
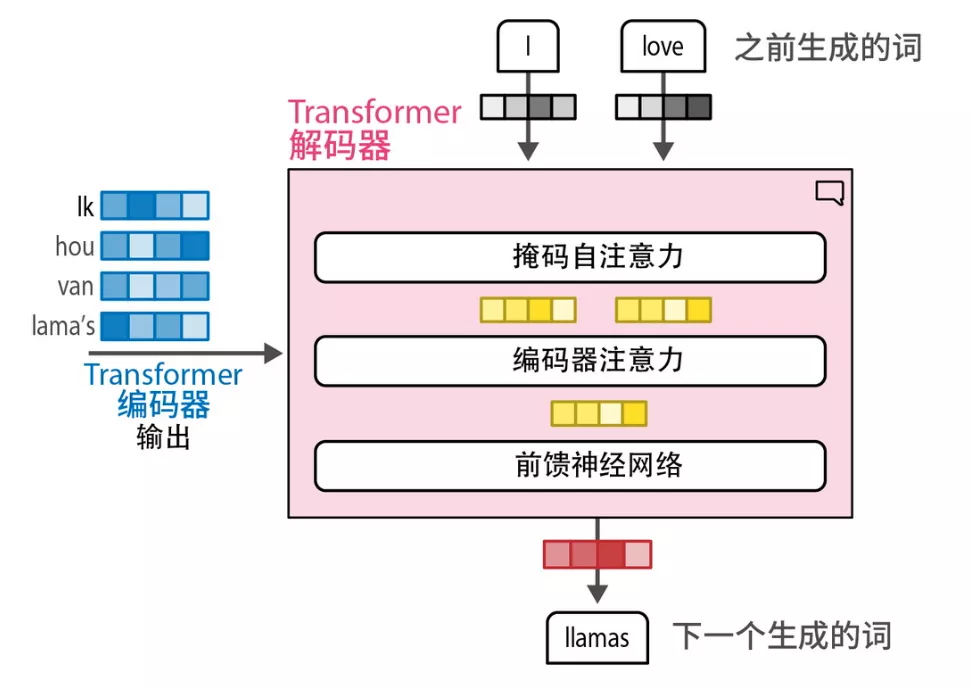
自注意力机制会计算权重向量,其中每个权重表示一个 token 对另一个 token 的重要性。上下文窗口的大小决定了模型一次能够处理的最大 token 数量。如果上下文窗口太小,模型可能会忽略 distant token 之间的重要关联;如果太大,模型则可能因信息量过大而难以应对。
更多大语言模型的图解及分析可以参考:

问题也正出在这里。
只要模型仍然主要依赖标准自注意力,那么上下文越长,要计算的 token 间关系就越多。工程上经常用 O(n^2) 来描述这个趋势:输入长度翻倍,计算和显存压力通常不只是线性增加,而会涨得更快。
上下文窗口越大:
- 推理更慢
- 成本更高
- 显存和缓存压力更大
- 更需要做检索、摘要和重排,否则很容易把昂贵预算浪费在低价值信息上
3. 长上下文问题不只有性能退化,还有安全暴露面扩大
很多人谈长上下文,第一反应是“会不会忘”“会不会 lost in the middle”。这些当然重要,但还不够。
对 Agent 来说尤其如此。Anthropic 在 Building effective agents 里把 Agent 概括成带有 retrieval、tools、memory 的 augmented LLM;OpenAI 在 Model Spec 里也把 system、developer、user、tool 视为会共同进入模型处理流程的消息层级。这意味着一轮推理里混在一起的,往往不只是用户当前提问,还可能包括历史对话、检索片段、网页内容、第三方文档、工具返回、上传文件,甚至代码与脚本输出。
问题在于,这些内容并不都值得信任。Greshake 等人在论文 Not what you've signed up for 里展示了 indirect prompt injection:攻击者可以把恶意指令藏进更可能被检索到的网页、文档或共享内容里,让模型把原本只是“数据”的文本误当成新的“指令”。OpenAI 在 Understanding prompt injections 里也明确提醒,外部内容里的隐藏指令往往会伪装成普通文本,而文件附件、检索结果、工具输出等输入通道,都会成为提示注入的载体。
所以更准确地说,风险上升的并不只是“窗口更长”这一个参数,而是:上下文一旦变长,系统通常也会为了完成任务接入更多外部数据和工具;而当模型拥有更高权限、要执行更长链路任务时,攻击面就会继续扩大。 模型此时不只是更容易“看漏关键事实”,也更容易把“不该执行的话”误当成“应该服从的约束”。
如何压榨有效的上下文窗口
在“有限注意力预算”的约束下,优秀的上下文工程目标是:用尽可能少、但高信号密度的 tokens,最大化获得期望结果的概率。核心目的是信息充分但紧致:
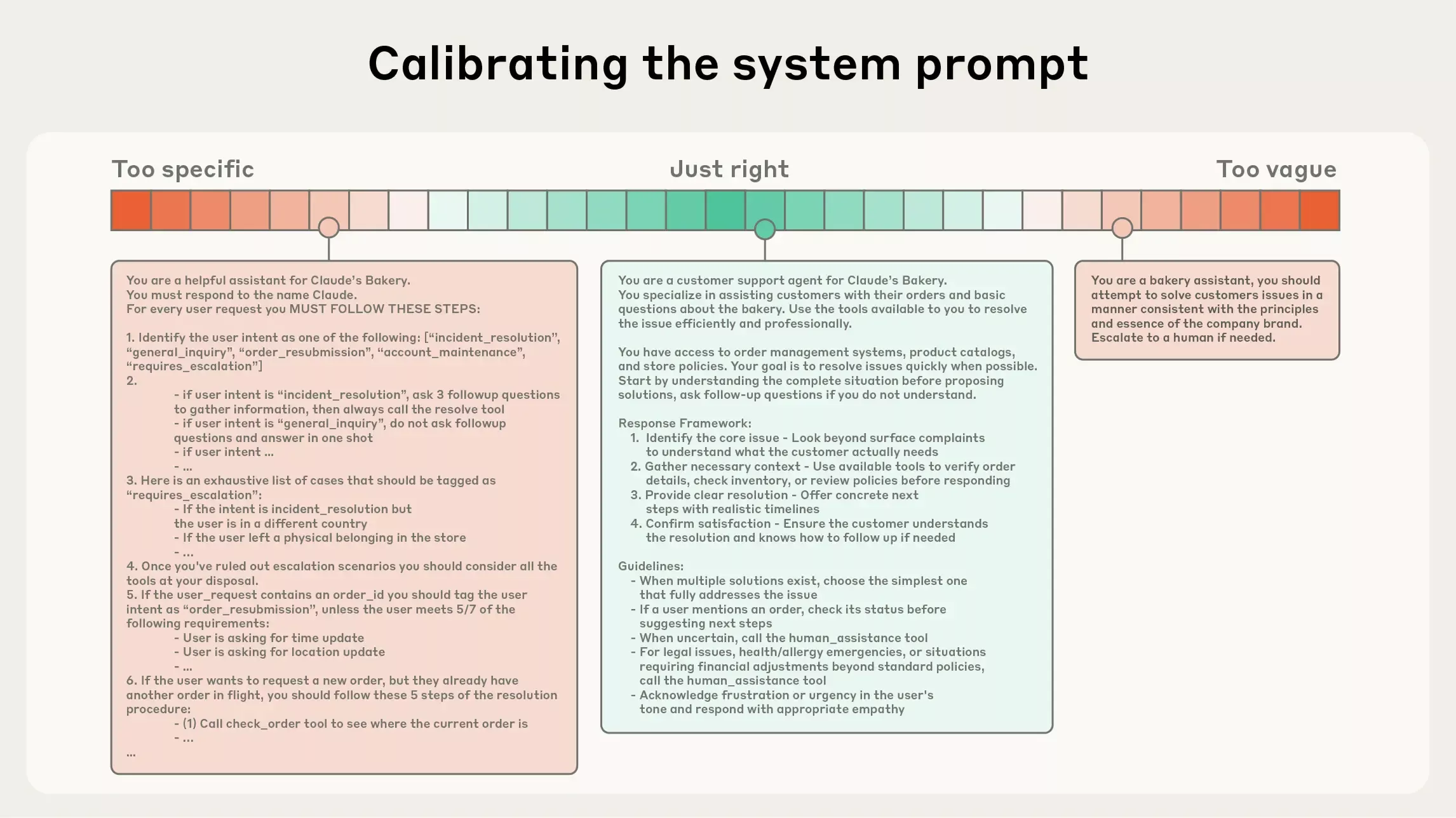
-
系统提示(System Prompt):语言清晰、直白,信息层级把握在“刚刚好”的高度。(这个比较经验性)
-
工具(Tools):工具定义了智能体与信息/行动空间的契约,必须促进效率:既要返回token 友好的信息,又要鼓励高效的智能体行为。如果人类工程师都说不准用哪个工具,别指望智能体做得更好。
-
示例(Few-shot):始终推荐提供示例,但不建议把“所有边界条件”的罗列一股脑塞进提示。请精挑细选一组多样且典型的示例,直接画像“期望行为”。对 LLM 而言,好的示例胜过千言万语。
Augment Context Engine 是如何处理大型项目的
Augment Code 面世时就因为大型任务处理能力而很出名。它的核心除了更强的 agent,本质上也离不开 ACE(Augment Context Engine) 这套上下文引擎:
当项目大到根本不该“全部塞进 prompt”时,我们怎样让 Agent 仍然觉得自己像看见了整个代码库?
这正是上下文工程最有价值的落地方向。
根据 Augment 的 官方页面、MCP 文档 和官方博客,Augment 的思路非常明确:上下文质量比上下文长度更重要。它并不把“长窗口”当成核心卖点,而是把重点放在“如何维护一个对代码库的实时、结构化、可检索理解”上。
它公开讲到的几件事,正好对应了大型项目里最常见的上下文损失来源。
不少其他AI编程工具也在开发自己的上下文引擎,后续也会单独针对 ACE 及其他各家做一个综合分析:
1. 先做持续索引,而不是每轮临时暴力搜索
Augment 会对工作区进行自动索引,并且索引会随着代码变化实时更新。官方文档 里提到,工作区通常在打开后自动上传并建立索引;官方博客 又进一步解释,它们维护的是每个开发者的实时个人索引,这样切分支、改文件、批量重命名之后,检索上下文仍然能快速跟上。
这一步很关键。因为大型代码库的第一个问题从来不是“模型不够长”,而是上下文很快过时。如果检索看到的还是十分钟前的代码,Agent 就算有再大的窗口,也是在吃旧数据。
2. 它检索的不是关键词,而是关系
Augment 在官网和 MCP 文档里反复强调,Context Engine 不是简单的 grep,也不只是关键词匹配,而是对代码进行语义索引和关系理解。
这部分底层
它要知道的不只是“哪个文件提到了 payment”,还包括:
- 哪些服务互相依赖
- 哪条调用链会经过哪些模块
- 哪些代码已经废弃
- 哪些模式是团队一直在重复使用的
这就解决了大项目里最难的一类上下文损失:模型虽然找到了词,但没找到结构。
3. 它会做上下文精选,而不是全文转储
Augment 官方在 Context Engine 页面写得很直接:它不会把整个代码库 dump 进 prompt,而是只检索和请求相关的部分,再对上下文进行压缩、排序和优先级整理。
这其实就是上下文工程最核心的一条原则:不是“塞得越多越好”,而是“信号密度越高越好”。
对大型项目来说,这种精选至少带来三个好处:
- 减少噪声,避免模型把注意力浪费在不相关模块上
- 降低 lost-in-the-middle 和上下文分散问题
- 让模型把有限注意力用在真正关键的依赖链、约定和边界条件上
4. 它把历史也做成可检索上下文
Augment 在 Context Lineage 的更新里又往前走了一步:不仅索引当前代码,还索引最近 commit 历史,并用轻量模型先把 diff 总结成更紧凑的搜索文档,再在需要时注入 prompt。
这个思路很妙。因为很多真实开发问题其实不是“这段代码现在长什么样”,而是:
- 为什么当初要这么写
- 这个 edge case 以前在哪次修过
- 有没有一个老 commit 已经做过类似模式
如果直接把原始 diff 塞进上下文,token 成本会非常高,噪声也重;但如果先把它压成结构化摘要,再按需召回,历史就从“上下文负担”变成了“上下文资产”。
有效上下文,最后拼的是工程
如果把这篇文章压缩成一句话,我会这样总结:
上下文工程不是研究“怎么把更多东西塞进去”,而是研究“怎样让模型在有限注意力里,只看到最值得看到的东西”。
这也是为什么我现在越来越觉得,Agent 时代真正的核心能力不是 prompt engineering 本身,而是下面这四个动作能不能被系统化执行:
- 写入:把长期有价值的信息写到上下文窗口外,比如记忆、笔记、提交历史摘要
- 选择:每一轮只拉回和当前任务最相关的部分
- 压缩:把大段日志、工具输出、长文档压成高信号版本
- 隔离:把不同子任务拆到不同上下文里,避免主线程被中间噪声污染
窗口会继续变长,模型也会继续进步,但这四件事不会过时。因为上下文从来都不是一个“有多大”的问题,而首先是一个“怎么用”的问题。
所以,与其把上下文窗口理解成一块越来越大的硬盘,不如把它理解成 Agent 的工作台。工作台再大,如果工具乱放、资料堆满、旧纸条和新任务混在一起,人还是会乱;模型也一样。
上下文工程真正做的,就是把这张工作台整理到模型能稳定发挥的状态。而所谓有效上下文,本质上就是:在这张工作台上,模型还能持续、准确、低噪声地完成任务的那一段真实可用空间。
参考资料
- Datawhale《Hello Agents》第九章:上下文工程
- Datawhale《Hello Agents》上下文工程补充知识
- Context-Engineering 仓库中文分支
- Anthropic:Context windows
- Anthropic:Long context prompting tips
- Lost in the Middle: How Language Models Use Long Contexts
- Extending Context Window of Large Language Models via Positional Interpolation
- YaRN: Efficient Context Window Extension of Large Language Models
- LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
- Gemini 1.5 Technical Report
- Chroma Research:Context Rot
- Augment:The Context Engine
- Augment Docs:Context Engine MCP Overview
- Augment Docs:Workspace Indexing
- Augment Blog:Announcing Context Lineage
- 上下文工程:agent时代的核心能力
- Understanding LLM Context Windows: Tokens, Attention, and Challenges