背景
随着Openclaw大火,苹果的mac mini已经卖爆了: 老实说,它走红是因为大家喜欢“在 Mac mini 本地跑 AI 代理、不上云”这个概念,感觉很有掌控感,还有点小黑客 vibe 哈哈。
我个人觉得openclaw理应使用本地模型跑,云端巨额的token花费实在体现不出他作为日常生活助手的特点(毕竟你也不想问个天气就花费5块钱吧🤣),我觉得很多人也是因为养不起而让龙虾放生吧。
虽然我没有mac mini,但是我突然想起来我有一块上大学时候购买的Nvidia Jetson Orin nano 8GB 板子,为了不让他吃灰下去,我决定试试本地模型推理。
Jetson Orin nano 8GB的配置
Jetson Orin nano 在2024年年底有一次软件升级,解锁了MAXN SUPER功耗挡位,CPU等超频了,提升了内存带宽,能进化到Jetson Orin nano Super
| 配置 | 说明 |
|---|---|
| AI 性能 | 67 INT8 TOPS |
| GPU | 搭载 1024 个 CUDA 核心和 32 个 Tensor Core 的 NVIDIA Ampere 架构 |
| CPU | 6 核 Arm® Cortex® -A78AE v8.2 64 位 CPU 1.5 MB L2+4MB L3 |
| 显存(显存和内存是共用的) | 8GB 128-bit LPDDR 5102 GB/s |
| 存储 | 支持 SD 卡插槽和外部 NVMe |
| 功耗 | 7 瓦 - 25 瓦 , 已经升级Super后的MAXN SUPER |
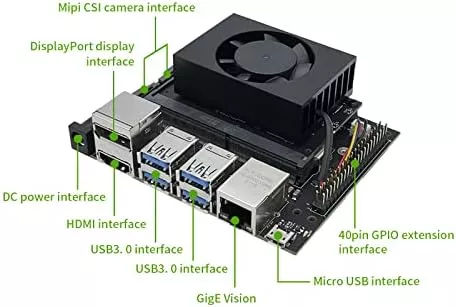
环境安装
刷机
刷机视频可以看:
其实我机子就是创乐博这买的,算是我看过最细致的了
不要完全跟着Nvidia SDK Manager走,如果想要升级为Super,需要参考:r36.5 NVIDIA Jetson Linux Developer Guide
安装Jetpack
NVIDIA JetPack SDK 是构建端到端加速 AI 应用的最完整方案,显著缩短模型部署时间开支。jetson orin nano Super最新的Jetpack版本为 6.2.2
安装分为两部分:
- 烧录系统镜像,遵循视频过程即可
- 安装Jetpack包,
sudo apt install nvidia-jetpack即可
Jetpack的主要组成是:
- Jetson Linux
- Jetson AI Stack
- Jetson Platform Services
详细的支持参照:Jetpack SDK
Jetson Linux
Jetson Linux:板级支持包(BSP),包含引导加载程序、Linux 内核、Ubuntu 桌面环境、NVIDIA 驱动、工具链等,并具备安全和空中升级(OTA)功能。
NVIDIA Jetson Linux 36.5 提供 Linux 5.15 内核、基于 UEFI 的引导加载程序、基于 Ubuntu 22.04 的根文件系统、NVIDIA 驱动、必要固件、工具链等。
更多的细节参考:版本发布说明
Jetson AI Stack
Jetson AI Stack:CUDA 加速的 AI 栈,提供一整套用于 GPU 计算、多媒体、图形和计算机视觉加速的库,支持 Metropolis 等应用框架来构建、部署和扩展视觉 AI 应用,支持 Isaac 构建高性能机器人应用,支持 Holoscan 构建从边缘到云的高性能计算(HPC)应用,实现实时洞察和传感器处理能力。
随 JetPack 6.2.2 打包的 Jetson AI 栈包括 CUDA 12.6、TensorRT 10.3、cuDNN 9.3、VPI 3.2、DLA 3.1 与 DLFW 24.0。
Jetson Platform Services
Jetson平台服务是一套预构建、云原生的软件服务和参考工作流,用于在Jetson上加速AI应用。这些服务模块化、基于API,可快速配置以构建生成式AI及其他边缘应用。目前涵盖AI服务到系统服务共15+项服务2
- AI 感知服务(使用 DeepStream)
- 视觉语言模型(VLM)AI 推理服务
- AI 分析 —— 将元数据转为时间序列洞察
- VST 传感器管理与存储
- Redis 消息总线
- API 与物联网网关
系统配置
网络配置
正常联网即可,可以给机器分配一个静态IP方便后续使用
VNC远程配置
VNC部分server端主要参照:亚博智能的文档,需要一个密码,输入lguu即可解锁
需要额外配置一个虚拟显示器,可以参考: Jetson orin nx免显卡欺骗器配置: VNC远程桌面连接orin 插或不插物理显示器均不影响和中断连接(headless模式)
- 使用windows连接的话直接modaxterm即可,既能SSH连接,也能用内置的VNC client
- 使用linux连接的话可以使用tiger VNC,效果很好
Jtop工具
JTOP安装可以去仓库:jetson_stats
扩容Swap
在 8 GB Jetson 上运行 4B 本地模型时,增加额外的交换分区会稳定得多。这在模型加载、编译以及长上下文推理时都会有所帮助。
sudo fallocate -l 8G /var/swapfile
sudo chmod 600 /var/swapfile
sudo mkswap /var/swapfile
sudo swapon /var/swapfile
echo '/var/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
swapon --show
安装python的虚拟环境
这里我习惯使用miniconda,如果你喜欢使用UV的话,请参考:https://docs.astral.sh/uv/
sudo apt update
sudo apt install -y git curl wget build-essential cmake libcurl4-openssl-dev python3-pip
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
./Miniconda3-latest-Linux-aarch64.sh
source ~/.bashrc
模型推理后端
| 序号 | 推理引擎 | 模型格式 | 引擎点评 | 性能 | 模型通用性 |
|---|---|---|---|---|---|
| 1 | pytorch(gpu) | checkpoints | 快速原型验证所有 HuggingFace 模型 | 慢 | 最高 |
| 2 | llama.cpp(cpu) | gguf | 快速原型验证所有 GGUF 模型,适合与 CUDA 协同进行异构计算 | 慢 | 高,开源社区活跃 |
| 3 | llama.cpp(gpu) | gguf | 快速原型验证所有 GGUF 模型,性能好于 1 | 较快 | 高 |
| 4 | tensorrt | onnx/trt | trt 引擎构建需要 4 倍于模型大小,难以发挥开发板的内存优势,不建议在嵌入式开发板上进行大 VLM 部署 | 未给出 | 较低,需先转换 ONNX |
| 5 | tensorrt-llm | model.safetensor | 英伟达推荐的大模型部署方式,目前支持的模型较 llama.cpp 少 | 最快,实测部分模型性能较 llama.cpp-gpu 后端能再快 10% 以上 | 中,依赖官方适配或自行适配 |
| 6 | CPM.cu | checkpoints | 面壁科技发布框架,仅对自家模型支持较好,不通用 | 未给出 | 低 |
| 7 | vllm/SGLang | model.safetensors | 去年部署时 Jetson 官方生态对这两框架的支持一般,未部署成功,目前可能支持有所好转,读者可以自行尝试 | 未给出 | 未给出 |
llama.cpp 部署
这里直接使用CUDA来加速编译,CUDA工具包已经通过jetpack省心的安装好了,直接开始即可:
构建中有一个可选的构建: 如需启用 HTTPS/TLS 功能,可安装 OpenSSL 开发库。若未安装,项目仍可编译并运行,但不支持 SSL。也就是不能通过llama来下载模型,不过它本来也下载的很慢,所以干脆不参与这部分编译
常规的CUDA加速编译通过:
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release
覆盖默认的CUDA架构:
- 首先需要记录你的nvidia设备的计算能力,可以去"CUDA: Your GPU Compute > Capability"查看,jetson orin nano 是
8.7 - 在 CMAKE_CUDA_ARCHITECTURES 列表中手动列出每个不同的计算能力。
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="87"
指定CUDA版本:jetpack里面的/usr/local/cuda-12.6/bin/nvcc
编译配置:
cmake -B build \
-DGGML_CUDA=ON \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_ARCHITECTURES=87 \
-DCMAKE_CUDA_COMPILER=/usr/local/cuda-12.6/bin/nvcc
编译执行:跑CUDA加速并行编译
注意不要使用默认的编译或者是多核编译,不然模型只能通过CPU跑
cmake --build build --parallel
我这里的jetson 跑并行老容易爆内存,不知道是不是体质的问题,也可以这样跑不并行的
cmake --build build --config Release
编译完成之后的可执行文件位于:
~/llama.cpp/build/bin
具体的llama.cpp位置取决于你clone的目录
可以通过如下命令确认:
~/llama.cpp/build/bin/llama-server --help是否准备就绪
如何下载模型权重
下载模型权重统一从huggingface的国内镜像访问下载
下载模型可以使用网页端访问:
 进行下载,不过速度一般
进行下载,不过速度一般
这里推荐使用hf-mirrors的专用下载工具:hfd进行下载,使用方法可用参考项目readme,需要提前下载安装aria2配套使用
模型权重文件
llama.cpp 主要使用的模型权重格式是 GGUF。我这里参考了 Hugging Face 社区文章 Common AI Model Formats

简单理解,GGUF 是一种面向推理和分发的单文件二进制格式,最初就是为 llama.cpp 生态准备的。模型通常先在 PyTorch 之类的框架里训练好,再转换成 GGUF,方便后续在本地设备上直接加载运行。
一份 GGUF 文件通常包含三部分:
- 元数据(metadata) 保存模型架构、版本、上下文长度、超参数、tokenizer 等信息。
- 张量元数据(tensor metadata) 保存每个张量的名称、形状和数据类型。
- 张量数据(tensor data) 也就是真正的模型权重。

这种设计很适合本地部署,因为 GGUF 支持 mmap(),模型加载更快,而且天然适合做量化。像我们经常看到的 Q4_K_M、IQ4_XS、IQ2_M、Q8_0 都是 GGUF 常见的量化方案:
Q4_K_M是最常见的折中方案,体积和效果比较平衡。IQ2_M更激进,适合显存或内存特别吃紧的设备。Q8_0更接近原始精度,但占用空间会明显更大。
对于 Jetson Orin Nano 这类边缘设备,GGUF 的优势会更明显,因为它本来就是为“尽量少占资源、尽量快启动、尽量方便分发”这件事设计的。

和其他常见格式相比,也可以这样理解:
- Safetensors 更偏向 Hugging Face / Transformers 生态,适合训练、微调、共享原始权重,安全性也更好。
- GGUF 更偏向本地推理,尤其适合
llama.cpp、Ollama 这类工具链。 - ONNX 则更强调跨框架和跨平台部署,适合移动端、浏览器和通用推理场景。
模型推荐
这里参考大模型竞技场测试:

模型命名
这里我以最近比较火爆的谷歌开源模型gemma4为例子说明,如果懂的话你就跳过本节即可
- 模型本体类
- gemma / llama / qwen / mistral
- 模型家族名
- 4 / 3 / 2
- 通常表示代际或大版本,比如 Gemma 4、Qwen 3.5、Llama 3。
- 7B / 8B / 14B / 32B
- 通常表示参数规模等级,B 是 billion,十亿级参数。
- 一般来说越大能力上限越高,但显存/内存/速度成本也越高。
有一些特殊的命名:
- E4B
- 这是 Gemma 4 的官方命名。
- E = effective parameters,有效参数。
- 4B 不是说总参数就严格等于 4B,而是这类模型按“有效参数规模”来标。
- 官方 Gemma 4 E4B 模型卡写的是大约 4.5B effective,包含 embeddings 后大约 8B total。
- A4B
- 也是 Gemma 4 的官方命名。
- A = active parameters,激活参数。
- 常见在 MoE 模型上,意思是模型总参数可能很大,但一次推理真正激活参与计算的只有一部分。
- 8x7B
- 常见于 MoE。
- 一般表示“8 个专家,每个专家大约 7B 规模”这类结构。
- 不代表推理时 8 个专家都会同时全开。
- 训练阶段 / 用途类
- pt
- pre-trained
- 预训练底模,偏“原始基础模型”。
- 更适合继续微调。
- it
- instruction-tuned
- 指令微调版,适合问答、聊天、助手任务。
- 在 Gemma 官方仓库里,-pt 和 -it 是成对出现的官方命名。
- instruct
- 和 it 很接近,通常也是指令微调。
- 不同项目有的写 it,有的写 instruct。
- chat
- 一般表示聊天对话优化版。
- 和 instruct 很像,但有些模型会把 chat 做得更偏多轮对话风格。
- base
- 常指基础版、未指令对齐版。
- 基本可近似理解为接近 pt,但具体还得看模型卡。
- 精度 / 量化类 这一类最容易让人混淆。核心原则是:
- F16 / BF16 / F32:这类还是浮点存储,接近原始权重格式
- Q... / IQ...:这类是量化后的压缩格式
- 数字越小,通常体积越小,但质量损失风险越高
浮点格式
- F32
- 32 位浮点。
- 最大最原始,几乎不压缩。
- 文件非常大,本地跑很少作为最终分发格式。
- F16
- 16 位 IEEE 754 半精度浮点。
- 常见高质量权重格式。
- 比 F32 小很多,但仍然比较占内存。
- BF16
- 16 位 bfloat16。
- 和 F16 一样是 16 位,但指数范围更大,常见于训练/推理框架。
- 在一些硬件和框架里比 F16 更稳。
传统量化格式
- Q4_0
- 4-bit 量化,老式方案。
- llama.cpp wiki 里写的是每个 block 32 个权重,公式是 w = q * block_scale。
- 体积小,但相对新量化方案通常不占优。
- Q4_1
- 也是 4-bit 老式方案。
- 相比 Q4_0 多了 block_minimum,公式变成 w = q * block_scale + block_minimum。
- 一般比 Q4_0 略好一些,但仍是 legacy 方案。
- Q5_0 / Q5_1
- 同上,只是主体位宽变成 5-bit。
- 体积更大,通常质量更高。
- Q8_0
- 8-bit 量化。
- 质量损失通常很小,但文件也明显更大。
- 常见于“想省一点空间,但尽量保真”的场景。
K-quant 系列
- Q4_K / Q5_K / Q6_K
- K 表示 k-quant 系列。
- llama.cpp 官方 wiki 把它列为独立家族,通常比老的 Q4_0/Q5_0 更先进。
- 它们用的是 super-block 结构。
- Q4_K_M
- 可拆成:
- Q4:主体 4-bit
- K:k-quant 家族
- M:变体等级
- llama.cpp 协作者在讨论里明确说过:S/M/L 就是 small / medium / large。
- 一般理解:
- S:更小,损失更大
- M:平衡档
- L:更大,更保真
- 对 Q4_K 来说,社区里常把 Q4_K 当作 Q4_K_M 的别名来写。
- 可拆成:
- Q5_K_M
- 比 Q4_K_M 更大一些,通常更保真。
- 本质仍是 K-quant,只是主体位宽从 4 提到 5。
- Q6_K
- 6-bit K-quant。
- 通常接近高保真,但内存占用进一步上升。
I-quant 系列
- IQ4_XS / IQ4_NL / IQ3_S / IQ2_XS / IQ2_XXS
- IQ 表示 i-quant 家族。
- llama.cpp wiki 把它单独列出来,特点是会利用 importance matrix 一类方法做更激进压缩。
- 常见后缀:
- XXS:extra extra small
- XS:extra small
- S:small
- M:medium
- NL:non-linear
- 这类通常更追求“在很低比特下保留尽量多效果”,但不同模型上表现差异比 K-quant 更明显。
- 容器 / 文件类型类
- .gguf
- GGUF 是 GGML 生态下的模型文件格式。
- 官方文档定义它是“给 GGML 及其执行器用于推理的模型存储格式”。
- 特点是单文件、带元数据、适合 llama.cpp 这类本地推理工具。
- LoRA
- 如果文件名里带 LoRA,通常表示这不是完整底模,而是 LoRA 适配器。
- vocab
- 一般表示只有词表/元数据,不是完整可推理权重。
- 00001-of-00003
- 分片模型。
- 表示这是 3 片里的第 1 片。
跑起来~
如果模型选择困难的话,huggingface的GGUF模型处有硬件能力能覆盖的模型版本:
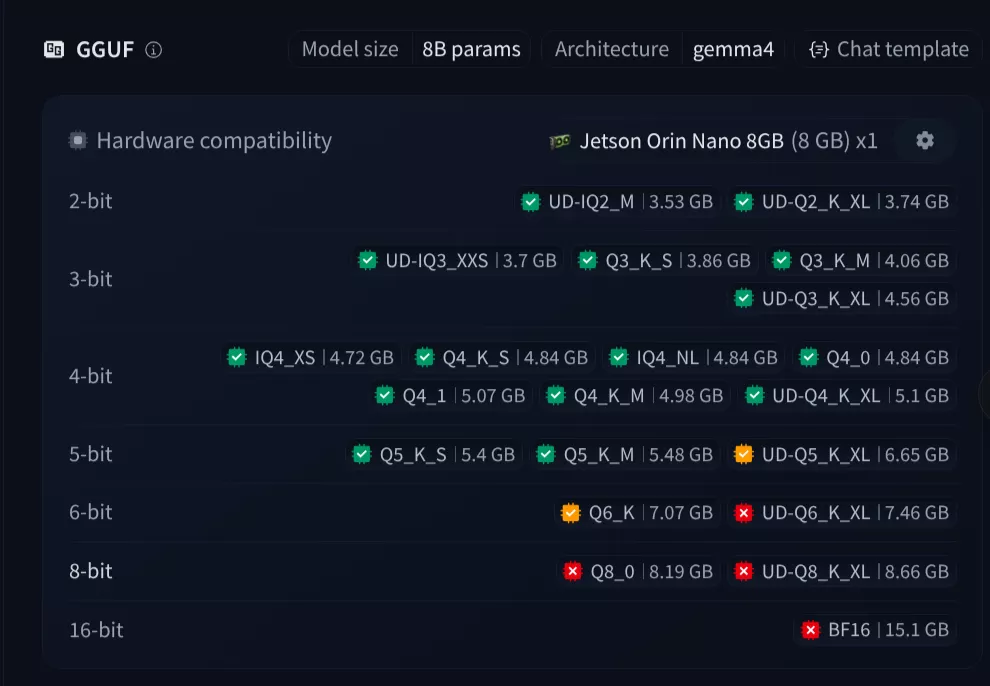
选择的话先从下往上依次尝试即可,跑不起来调级即可。
这里我选择的是unsloth/gemma-4-E4B-it-GGUF的 gemma-4-E4B-it-Q4_K_M.gguf版本 和 unsloth/Qwen3.5-4B-GGUF的Qwen3.5-4B-Q4_K_M.gguf版本
两个版本都处于平衡挡位
以gemma-4-E4B-it-Q4_K_M.gguf为例子,你需要首先cd到llama的项目目录
这里使用llama.cpp的轻量级、兼容 OpenAI API 的 HTTP 服务器,用于提供 LLM 服务。而且方便进行模型部署验证:
./build/bin/llama-server \
-m ~/llama.cpp/models/gemma-4-E4B-it-GGUF/gemma-4-E4B-it-Q4_K_M.gguf \
--alias gemma-4-E4B-local \
-t 6 \
-c 40960 \
--n-gpu-layers 40 \
--reasoning off \
--reasoning-format none \
--host 127.0.0.1 \
--port 8080
命令说明:
-m- 指定要加载的模型文件路径。
- 这里加载的是
gemma-4-E4B-it-Q4_K_M.gguf。
--alias gemma-4-E4B-local- 给当前模型起一个对外别名。
- 后续通过 OpenAI 兼容接口访问时,可以把它当成模型名
gemma-4-E4B-local来用。
-t 6- 指定生成阶段使用的 CPU 线程数。
- Jetson Orin Nano 是 6 核 CPU,这里直接给到
6
-c 40960- 指定上下文窗口大小
- 这个参数越大,占用的 KV cache 越多,对
8GB设备压力也越大。
--n-gpu-layers 40- 指定最多把多少层模型层放到 GPU 上执行。
- 这会直接影响推理速度和内存压力。
- 数值越大,通常越偏向让 GPU 干活;但如果内存不够,也更容易启动失败或者运行不稳。
--reasoning off- 关闭 reasoning / thinking 模式。
--reasoning-format none- 指定 reasoning 内容不做额外解析。
- 即使模型模板里有类似
<think>的结构,也不要单独提取到 reasoning 字段里。 - 这里和
--reasoning off搭配使用,本质上就是尽量把 thinking 通道关掉。
--host 127.0.0.1- 指定服务只监听本机回环地址。
- 这意味着只有这台 Jetson 自己能访问,局域网内其他设备默认访问不到。
- 如果你之后想让局域网里的电脑也能访问,可以改成
0.0.0.0。
--port 8080- 指定服务监听在
8080端口。 - 启动之后,就可以通过
http://127.0.0.1:8080访问这个本地模型服务。
- 指定服务监听在
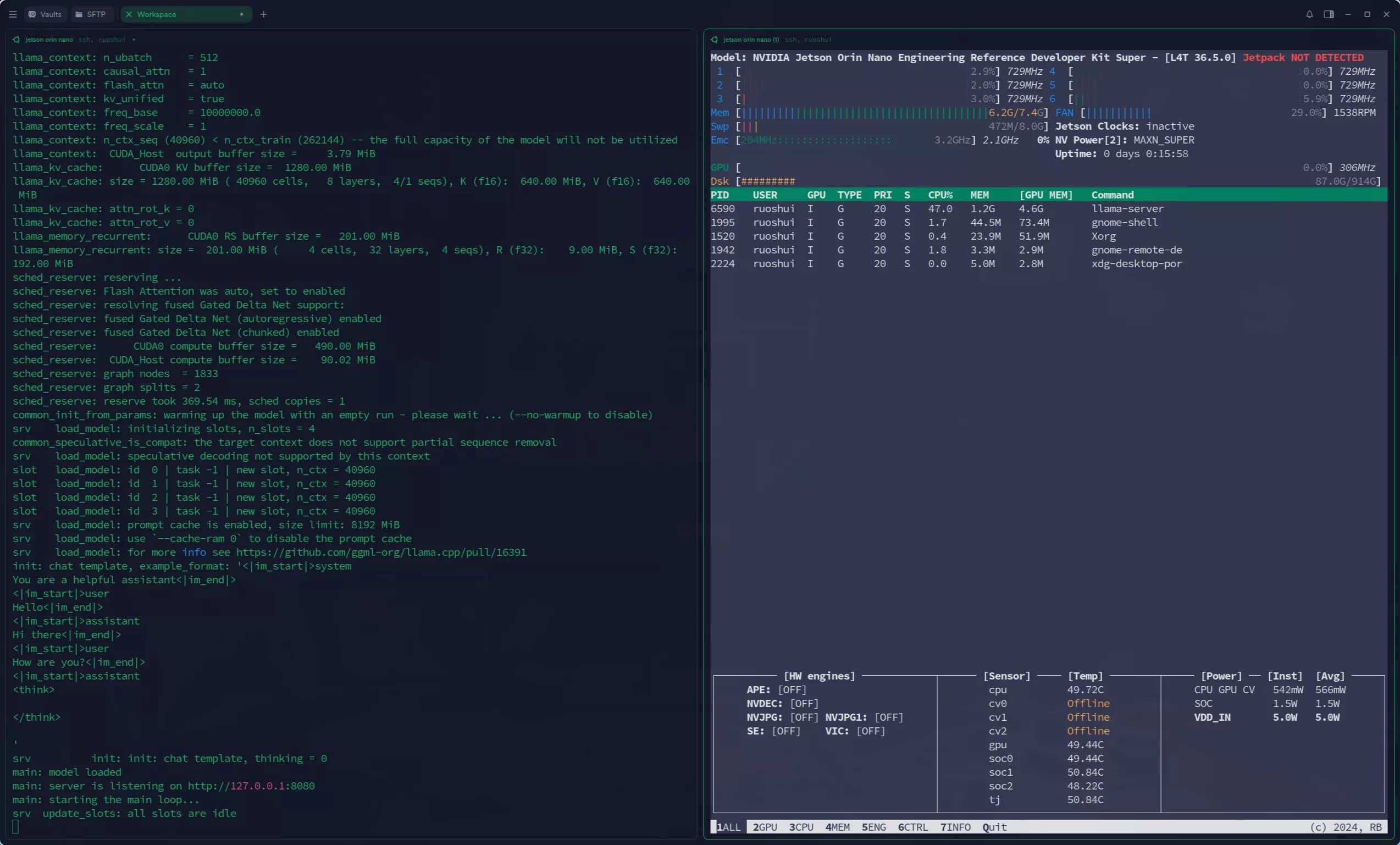
打开jtop能看到系统状态:
终端中请求curl http://127.0.0.1:8080/v1/models能看到:
{
"models": [
{
"name": "gemma-4-E4B-local",
"model": "gemma-4-E4B-local",
"modified_at": "",
"size": "",
"digest": "",
"type": "model",
"description": "",
"tags": [
""
],
"capabilities": [
"completion"
],
"parameters": "",
"details": {
"parent_model": "",
"format": "gguf",
"family": "",
"families": [
""
],
"parameter_size": "",
"quantization_level": ""
}
}
],
"object": "list",
"data": [
{
"id": "gemma-4-E4B-local",
"aliases": [
"gemma-4-E4B-local"
],
"tags": [],
"object": "model",
"created": 1775805084,
"owned_by": "llamacpp",
"meta": {
"vocab_type": 1,
"n_vocab": 262144,
"n_ctx_train": 131072,
"n_embd": 2560,
"n_params": 7518069290,
"size": 4961343656
}
}
]
}
模型运行成功,然后你就可以访问http://127.0.0.1:8080/对话